Start with the uncomfortable example.
A small data science team has five people using all-purpose Databricks clusters during the week. Each person starts a cluster, runs notebooks, explores data, tests features, gets pulled into meetings, goes for lunch, or simply closes the laptop at the end of the day. Nothing dramatic happens. The cluster just waits.
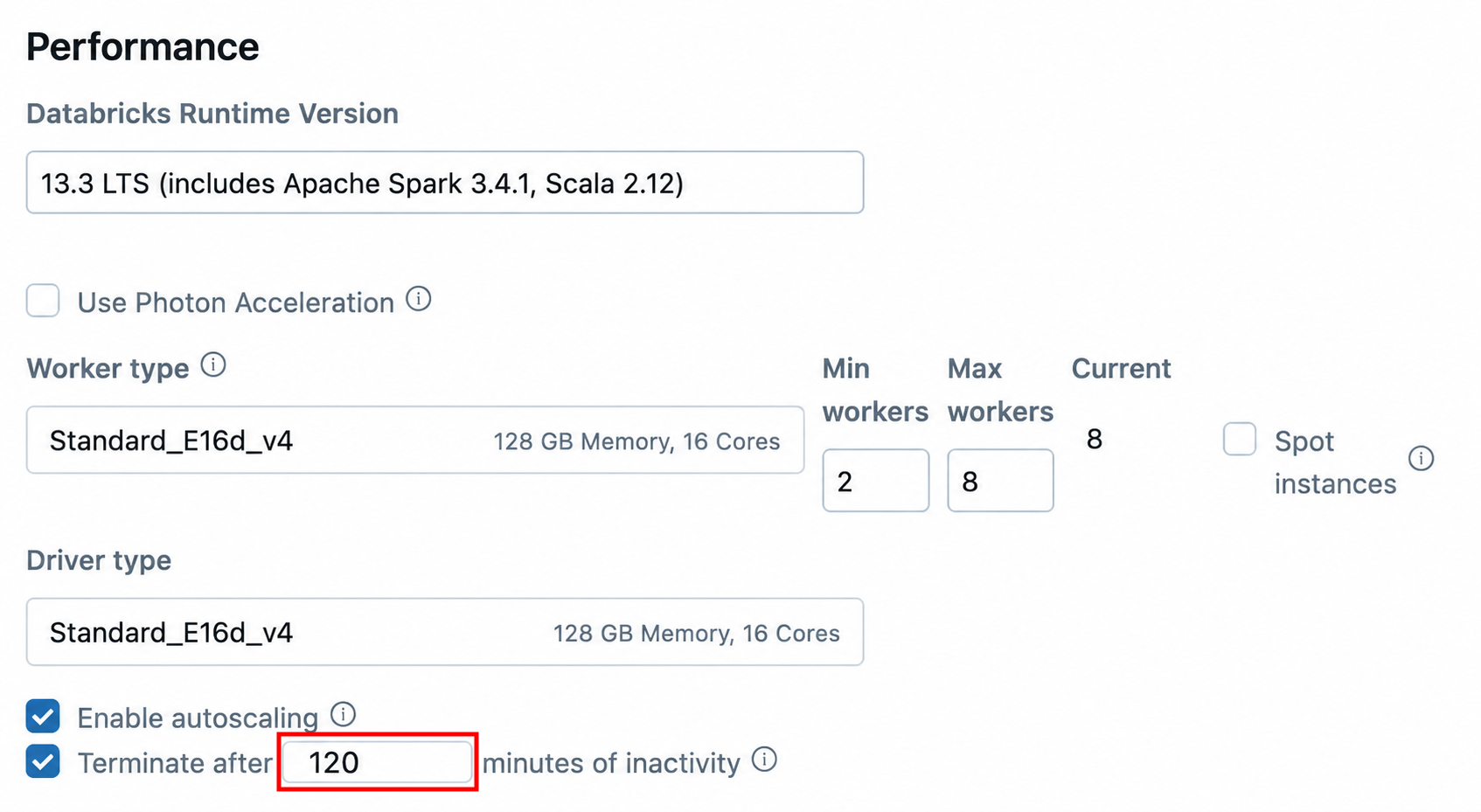
By default, Databricks clusters created in the UI will automatically terminate after 120 minutes of inactivity. That means a cluster can sit inactive for two paid hours before shutting down. The setting is also buried under Advanced Performance Settings, which is why it is so often missed, ignored or treated like a technical detail rather than a financial control. If each user leaves one cluster idle once per day, that is:
5 users
x 2 idle hours per day
x 22 working days
= 220 idle cluster hours per monthIf the full cluster cost is only $12 per hour, including Databricks DBUs and cloud compute, that small team is now looking at:
220 idle hours
x $12 per hour
= $2,640 per monthThat is before anyone has made a bad architectural decision. Before production has scaled. Before the estate has become complicated. This is just paid inactivity from a default setting nobody felt responsible for changing.
“Idle compute is not free compute. It is paid waiting time.”
The trap is thinking auto-termination solved the problem
Auto-termination is useful, but it is not the same thing as cost optimisation. A two-hour timeout is better than no timeout, but that is a low bar. If the useful work finished after ten minutes and the cluster stayed alive for another 120, the platform still spent money for no business output.
This is why idle compute is so dangerous. It does not look like a failure. There is no broken pipeline, no angry dashboard user and no alert in the middle of the night. The only signal is the bill, and by the time finance asks the question, the waste has already happened.
The seriousness of the issue is not the single idle cluster. It is the repetition. One abandoned notebook session feels harmless. Hundreds of them across a month become a budget line. Across multiple teams and workspaces, the number stops being annoying and starts becoming indefensible.
How to measure the leak
The practical metric is avoidable idle runtime. You are not trying to punish people for using compute. You are trying to find the paid minutes after useful activity stopped.
avoidable_idle_minutes =
max(0, observed_idle_gap_minutes - target_auto_termination_minutes)
idle_cost_leakage =
avoidable_idle_hours * hourly_cluster_costThe target auto-termination window is the timeout you believe is actually acceptable. For many interactive data science workloads, that might be 30 minutes rather than 120. The difference matters.
In the example above, moving from 120 minutes to 30 minutes changes the monthly idle exposure from 220 hours to 55 hours. At $12 per hour, that is roughly $1,980 of avoidable monthly leakage from one small team.
The question is not whether the cluster eventually shuts down. The question is how much money disappears before it does.
What good measurement looks like
A useful FinOps view should reconstruct each cluster session. When did the cluster start? When did useful activity happen? When did the last command, notebook, job or query finish? When did the cluster terminate? The leak is the gap between meaningful work ending and the point where the cluster should have been shut down.
Then convert that gap into dollars using the full hourly cost of the cluster. Looking only at Databricks DBUs can understate the problem. Looking only at cloud infrastructure can miss the platform charge. The real cost is the complete compute footprint kept alive for no reason.
This changes the conversation from:
“Maybe we should reduce auto-termination.”
to:
“This team leaked $1,980 last month because idle clusters waited two hours instead of thirty minutes.”
One is a suggestion. The other is a control failure with a price tag.
The governance problem underneath
Idle compute is usually an ownership problem pretending to be a configuration problem. Someone created the cluster. Someone used it. Someone left it waiting. But nobody owns the silent period after the work finished and before the platform finally terminated the resource.
Not every cluster should have the same timeout. Some teams need warmer interactive environments. Some development patterns justify longer windows. But those exceptions should be deliberate, tagged and reviewed. A 120-minute timeout without evidence is not convenience. It is an open purchase order.
The practical answer
Measure idle leakage by comparing actual inactivity gaps against the termination window you would be willing to defend. Convert the avoidable portion into dollars. Rank the leakage by team, workspace, cluster policy, owner and cluster type. Then fix the defaults before the behaviour spreads.
In a small environment, idle compute feels like housekeeping. In a growing Databricks estate, it becomes one of the quietest ways budget disappears.
If your all-purpose clusters can sit idle for 120 minutes, you do not just have a timeout setting. You have measurable cost leakage. And once the leakage is measurable, leaving it alone becomes a decision.